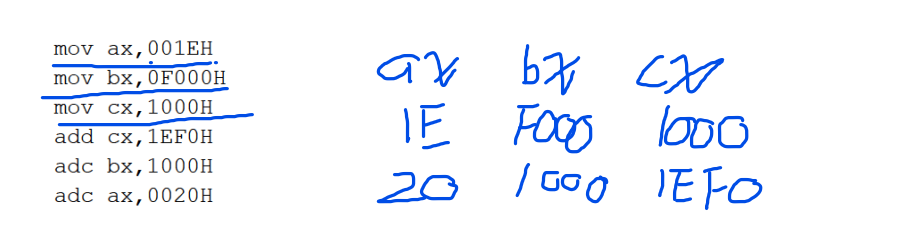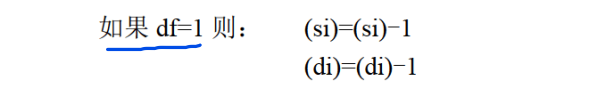debug中的常用命令
g 加地址,直接跳转至此处,前面全部执行
u 将内存中的机器指令翻译成汇编指令
t 执行一条指令
r 查看寄存器中的值,同时显示出下一条要执行的指令,还可以改变寄存器中的内容,比如r ax,然后弹出冒号,输入即可
d 查看内存中的内容,d 段地址:偏移地址 (可以在此处加上想查看的范围,默认是128字节),之后再按d显示后续内容
p 可以跳过loop循环
e 向内存单元写入命令,e 段地址:偏移地址 B8 01 00,即向该内存写入mov ax,1命令
第7章 更灵活的定位内存地址的方法
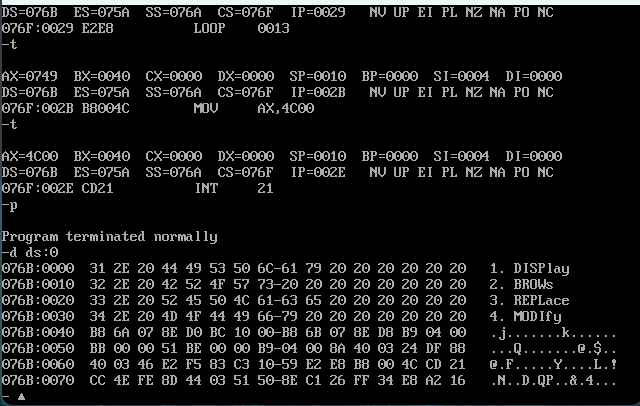
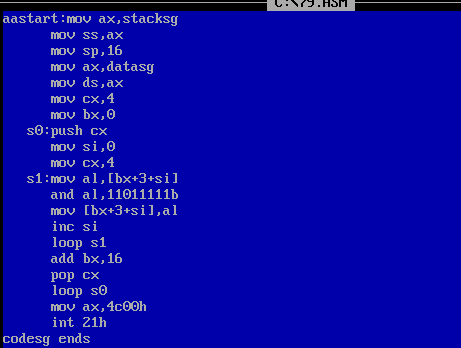
话不多说,直接上图,完成了任务。只不过忘掉了如何一次性执行完循环,一直t加回车,头皮发麻。这一题是让我们补充codesg段的代码,我们要灵活的利用栈来存储和释放cx
s0处的push cx是将外层循环的cx值压入栈中,然后往下执行,mov cx,4设置内层循环次数,执行完4次s1后,此时的cx值为零,将之前cx的值弹出栈,恢复为3(即4-1),然后往复执行。
tips 快速结束循环
再补充一个快速的指令 g 偏移地址,例如g 0012执行后,ip=0012,从此处开始往下执行。
第8章 数据处理的两个基本问题
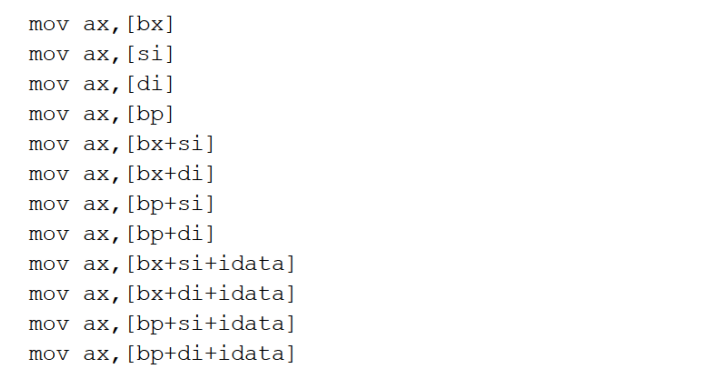
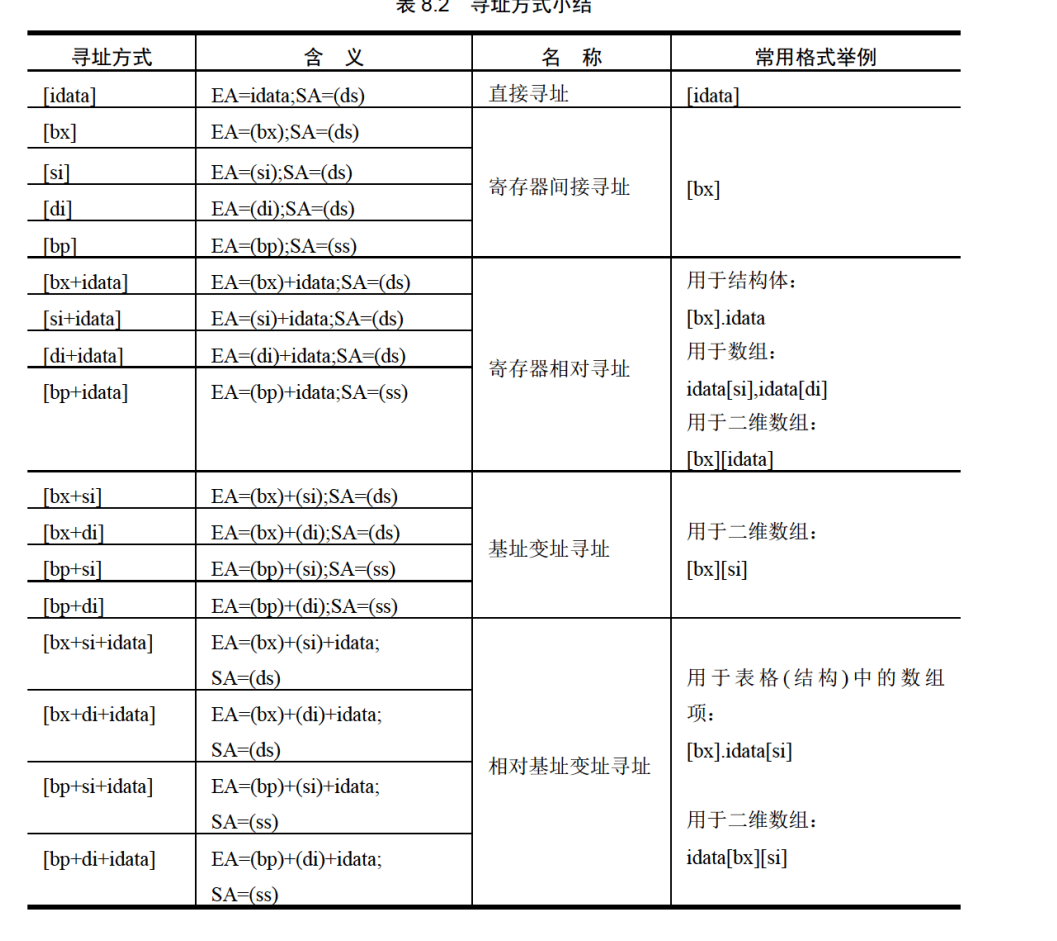
只有上述形式是是正确的,有个小要点,[bp]默认的段地址是ss。
指令要处理的数据有多长 这是我们必须指出的,可以显性地指出也可以隐形的指出,比如在有寄存器名称的情况下我们可以判断出访问的是字单元还是字节单元,在没有寄存器参与的情况下用操作符X ptr指明长度。X为byte或word。对于push [1000]这样的指令则无需指明,因为push指令只进行字操作。
实验 7
废了九牛二虎之力终于用比较朴素的方法实现了。遇到了不少问题,其中最主要的两个是:
error A2052: Improper operand type
g命令之后卡死
第一个在经过Google之后找到了解答
我记得这一点书上好像提到过,给忘掉了,真是一头雾水
第二个问题,算是摸索着解开了疑惑,网上说有三种情况,1.代码段没加mov ax,4c00h 2.重启解决 3.代码导致g命令出错
我的情况应该是属于第三种,因为我按自己的想法写的时候,寻址方式比较奇怪。比如说我成功之前的那一次
疑惑 1 2 3 4 div word ptr [bx].0Ah//g命令后卡死,虽然这两处的值不相同,但按道理来说结果会出错,不应该出现程序卡死,此处存有疑惑 div word ptr [bx+0ah]//也不可行 div word ptr es:[bx+0ah]//成功,上边的错误在于忘记了要标明es段,可是有一点存疑,就算用的是ds段地址,那同样也能读取数据,为什么会卡死呢????? div word ptr [168+si]//正确
寻址方式小结
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 assume cs:codesg //写的比较朴实,可能有较多重复的步骤,也可以一次循环填充一行中的所有信息,然后循环 data segment //21次即可 db '1975','1976','1977','1978','1979','1980','1981','1982','1983' db '1984','1985','1986','1987','1988','1989','1990','1991','1992' db '1993','1994','1995' dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514 dd 345980,590827,803530,1183000,1843000,2759000,375000,4649000,5937000 dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226 dw 11542,14430,15257,17800 data ends table segment db 21 dup('year sumn ne ?? ') table ends codesg segment start:mov ax,data mov ds,ax mov ax,table mov es,ax mov bx,0 mov si,0 mov cx,21 s0: mov ax,[si] mov es:[bx],ax add si,2 mov ax,[si] mov es:[bx+2],ax add si,2 add bx,16 loop s0 mov bx,0 mov si,0 mov cx,21 s1: mov ax,[84+si] mov es:[bx+5],ax add si,2 mov ax,[84+si] mov es:[bx+5+2],ax add si,2 add bx,16 loop s1 mov bx,0 mov si,0 mov cx,21 s2: mov ax,[168+si] mov es:[bx+0Ah],ax add bx,16 add si,2 loop s2 mov bx,0 mov si,0 mov cx,21 s3: mov ax,es:[bx+5] mov dx,es:[bx+5+2] div word ptr [168+si] mov es:[bx+0Dh],ax add si,2 add bx,16 loop s3 mov ax,4c00h int 21h codesg ends end start
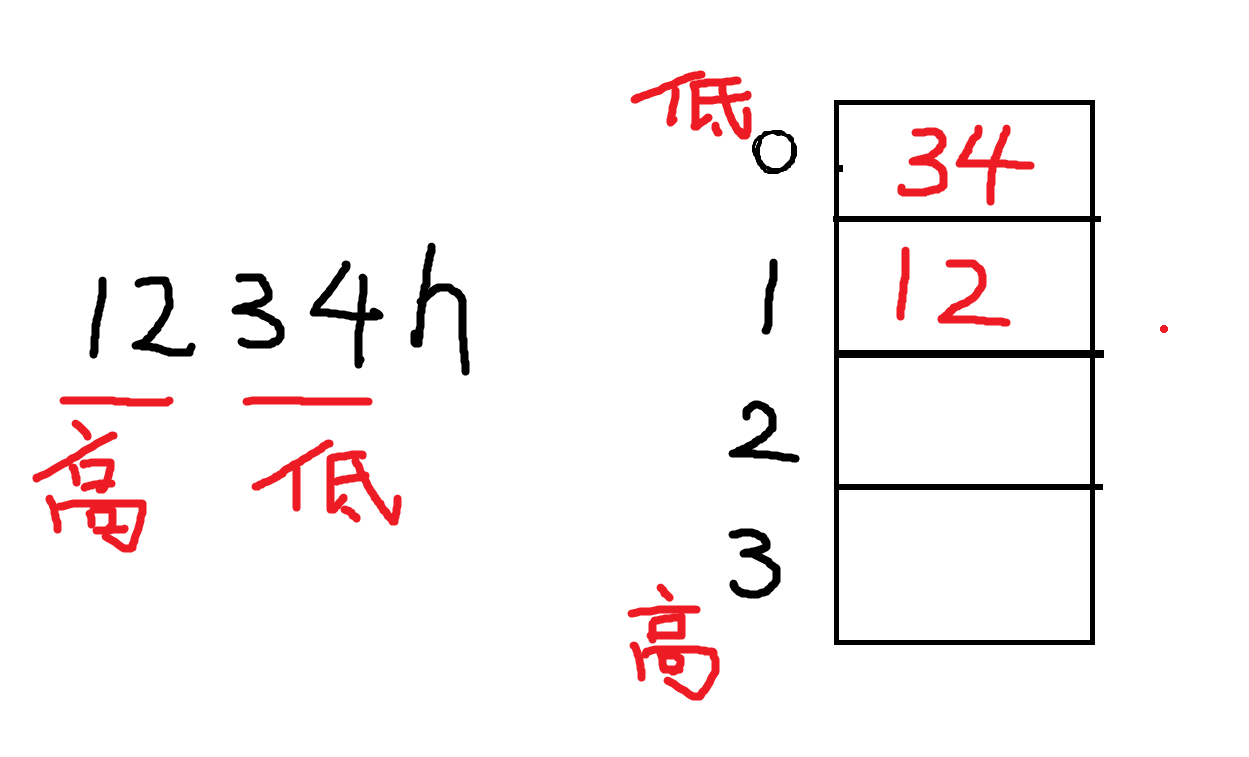
通过这次的实验知识发现了不少短板,hhh或者说全是短板哈哈哈哈,很多基础的东西打的不是很牢固,比如说高低字节,高低位
高低字节,高低位 1 2 对于 1234 h这个十六进制数来说,其高字节是12 ,低字节是34 我们平时接触小端序比较多,那么高字节12 存放在高地址单元中,低字节34 存放在低地址单元中
如果我们进行div word ptr ds:0操作,那么处理的也就是0、1这两个内存单元组成的数1234h。
第九章 转移指令的原理 操作符offeset offeset在汇编语言中是由编译器处理的符号,它的功能是取得标号处的偏移地址
转移指令 jmp指令 CPU在执行jmp指令的时候不需要转移的目的地址,需要的是位移量。
转移的目的地址在指令中的jmp指令
可以看到,这里是通过目的地址而非位移量进行转移的
转移地址在内存中的jmp指令 jmp word ptr 内存单元地址(段内转移)
jmp dword ptr 内存段地址(段间转移)
对于段间转移 (CS)=(内存单元地址+2),
(IP) =(内存单元地址)
jcxz指令 有条件的段间转移,有条件转移都是段间的,在对应的机器码中包含位移而不是地址。当cx==0的时候执行跳转,cx!=0时直接执行下一条语句
loop指令 循环指令都是段指令,对应的机器码中包含位移地址而不是目的地址
实验八 分析一个奇怪的程序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 assume cs:codesg codesg segment mov ax,4c00h int 21h start: mov ax,0 s: nop nop mov di,offset s mov si,offset s2 mov ax,cs:[si] mov cs:[di],ax s0: jmp short s s1: mov ax,0 int 21h mov ax,0 s2: jmp short s1 nop codesg ends end start
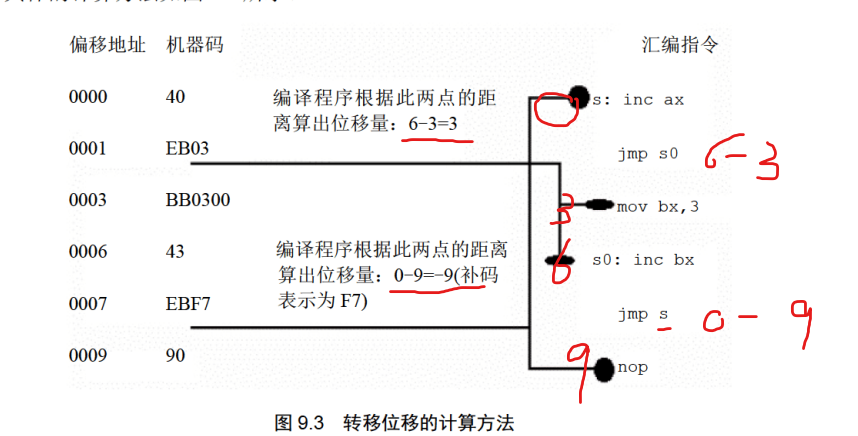
虽然看着是挺奇怪的,s的操作就是使s处的命令变为s2处的命令,即跳转到s1,很显然mov ax,0这里不满足让程序正确返回,用debug的t命令进行调试,可以成功运行,我们知道jup命令是不带有目标位置的地址的,它含有一个偏移地址,s2处的jump short s1的机器码是EB F6,F6就是偏移地址1111 0110补码表示-10,-10含义是标号处的地址-jmp指令后的第一个字节的地址,也就是从mov di,offset s位置前移十个字节,正好到达mov ax,4c00h int 21h,程序得以成功返回
实验九 将’welcome to masm!’正好16个字符,填入第11、12、13行
绿色属性 0 000 0 010B 02h
绿底红字属性 0 010 0 100B 24h
白底蓝色属性 0 111 0 001B 71h
经过不懈的努力终于是搞好了,困住我的主要有两点,其一是对字,字节,寄存器不敏感,对于传输字和字节有点生疏。其二就是让我崩溃的东西,题目要求是打印在中间,我一想80个字符位,左边空出32,右边空出32中间正好留下16,然后左边的32x2=64,有因为是从零开始,所以这边我们第一个填充的位置就是64呀,当成了63操作,结果是真抽象,还好最后一试,将welcome全部改成了11111,打印出来发现全部是同一个颜色的符号,也就是说我的颜色就然和字符与关,果断想到填充错了位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 assume cs:codesg,ds:data data segment db 'welcome to masm!' data ends codesg segment start:mov ax,data mov ds,ax mov di,0 mov cx,16 mov bx,0 mov ax,0B800h mov es,ax mov si,06e0h mov ah,02h s0:mov al,ds:[di] mov es:[bx+si+64],al mov es:[bx+si+65],ah add bx,2 add di,1 loop s0 mov ax,0B800h mov es,ax mov di,0 mov bx,0 mov si,780h mov cx,16 s1:mov al,ds:[di] mov es:[bx+si+64],al mov al,24h mov es:[bx+si+65],al add bx,2 inc di loop s1 mov ax,0B800h mov es,ax mov bx,0 mov di,0 mov si,820h mov cx,16 s2:mov al,ds:[di] mov es:[bx+si+64],al mov al,71h mov es:[bx+si+65],al add bx,2 inc di loop s2 mov ax,4c00h int 21h codesg ends end start
第十章 CALL指令和RET指令 ret和retf ret指令只修改ip的内容,实现近迁移,retf应该就是ret far的意思,同时修改cs和ip中的内容,实现远迁移。
用汇编语言解释
ret:POP IP
retf:POP IP ,POP CS
CALL指令
依据位迁移进行转移的call指令
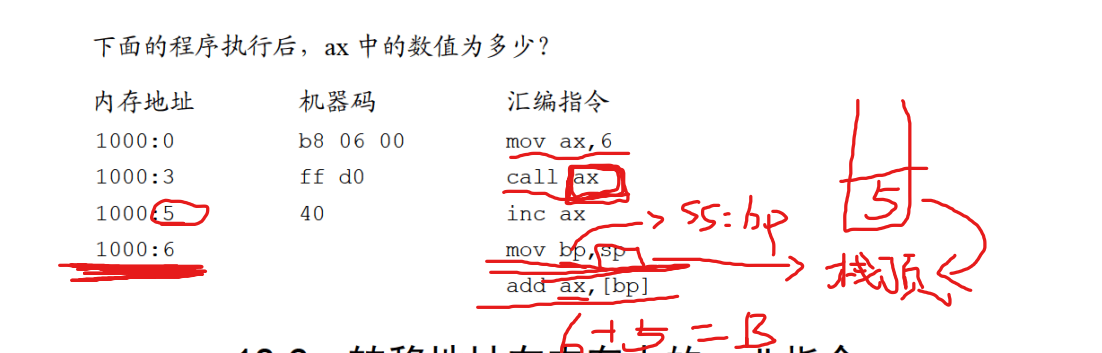
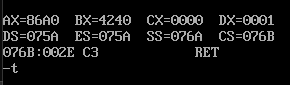
下面程序执行后,ax的值
读取过call s指令后,ip中的值自动增加(第二章 28页),变为6,call指令相当于push ip,s处是pop ax,所以ax的值为6。
转移的目的地址在指令中的call指令
转移地址在寄存器中的call指令
bp的默认段地址是ss
转移地址在内存中的call指令
回顾一下jump dword ptr 内存单元地址
CS=(内存单元地址+2)
IP=(内存单元地址)
mul指令
实验 10 编写子程序 1.显示字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 assume cs:code,ss:stack data segment db'welcome to masm!',0 data ends stack segment db 8 dup (0) stack ends code segment start:mov dh,8 ;传参 8行 3列 绿色 mov dl,3 mov cl,2 mov ax,data mov ds,ax mov si,0 call show_str mov ax,4c00h int 21h show_str: sub dh,1;这里注意000是第一行开始,160是第2行开始 mov al,160 mul dh;存入的数据是7*160,即第八行开始 mov bx,ax mov dh,0 add bx,dx add bx,dx;这里实现列数,注意两个字节表一个字符,所以我们加两次即加6 mov ax,0b800h mov es,ax mov al,cl s:mov cl,[si] mov ch,0 jcxz ok;如果是结束字符0,则跳转回去 mov es:[bx],cl mov es:[bx+1],al inc si add bx,2 jmp short s ok: ret code ends end start
由于粗心出现了一个警告 missing data:zero assume,提醒我们缺少操作数
把add bx,dx写成了add bx,dx
2.解决除法的溢出问题
给出了一个提示
65536是十六进制的1 0000也就是将得到的数左移四个16进制位呗,我们可以直接把int(H/N)的内容直接放入dx中,然后把后面的整体装入ax中,把后面整体产生的余数装入cx中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 assume cs:code,ss:stack stack segment dw 8 dup (0) stack ends code segment start:mov ax,stack mov ss,ax mov sp,10h mov ax,4240h mov dx,000fh mov cx,0ah call divdw mov ax,4c00h int 21h divdw:push ax push dx mov bx,ax mov dx,0 pop ax div cx push ax;商 push dx;余 mov ax,bx div cx mov cx,dx pop dx pop dx pop si;它存在的意义是把栈清理到只剩一个,以便使下面的ret成功返回 ret ;前面哪些部分其实可以不使用栈,此题占用的寄存器不多 code ends end start
3.数值显示将二进制转化为十进制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 assume cs:code data segment db 10 dup (10) data ends code segment start:mov ax,12666 mov bx,data mov ds,bx mov si,0 call dtoc mov dh,8 mov dl,3 mov cl,2 call show_str mov ax,4c00h int 21h dtoc:mov dx,0 mov bx,10 div bx;余数在dx,商在ax mov cx,ax add dx,30h mov [si],dl;存放余数的ascii inc si;表示位数 jcxz short s1 jmp short dtoc s1:ret show_str: sub dh,1 mov al,160 mul dh mov bx,ax mov dh,0 add bx,dx add bx,dx mov ax,0b800h mov es,ax mov al,cl s:mov cl,[-1+si];66621 mov ch,0 ;jcxz ok 如果不注释掉的话,以零结尾的数将无法显示 mov es:[bx],cl mov es:[bx+1],al sub si,1 mov cx,si jcxz short ok add bx,2 jmp short s ok: ret code ends end start
感谢这位博主:https://blog.csdn.net/qq_60829702/article/details/123582250
第十一章 标志寄存器
ZF 标志 记录相关指令执行后结果是否为零,如果为零则ZF为1,如果非零则ZF为0。
PF 标志 记录执行相关指令后,结果的所有bit位1的个数是否为偶数,如果1的数量是偶数,则PF为1.
SF 标志 记录执行相关指令后,结果是否为负,如果结果为负,则SF为1.
CF 标志 在进行无符号运算时,它记录进位和借位情况
进位比较好理解,下面看一下借位
OF 标志 进行有符号运算是否发生溢出,如果溢出则OF为1.
adc 指令
这个指令乍一看很奇怪,很多余,为什么要加上一个cf?但是看了下面的解释之后,我直呼巧妙
adc也会对CF位进行设置,由于这样的功能,我们可以对任意大的数据进行加法运算。
sbb 指令
cmp 指令
可以通过标志寄存器中的值得出比较结果
这里有点疑惑的,为什么实际结果为负,且发生了溢出,就可以推出实际结果为正。溢出,有正溢出和负溢出。正溢出就是两个正数相加,超过了能表示的最大范围,变为负数,负溢出就是两个负数相加,超出了能表示的最小范围,变为正数。举个例子:
1 2 3 4 5 拿四位有符号数来举例 MAX ==0111==7MIN ==1000==-8正溢出0111+0111 ==1110(补码)==-2 负溢出1000+1000 ==10000截断最高位==0000两个负数相加结果为0
好的疑惑消失了。
检测比较结果的条件转移指令 这些指令往往和cmp搭配使用,因为cmp可以同时进行两种比较,无符号数比较和有符号数比较。
DF标志和串传送指令
串传送指令:movsb,实现传送一个字节,movsw实现传送一个字
movsb一般和rep搭配使用
pushf 和 popf
push 和 pop显然不能进行这些操作,他两个的操作对象是字而不是bit。
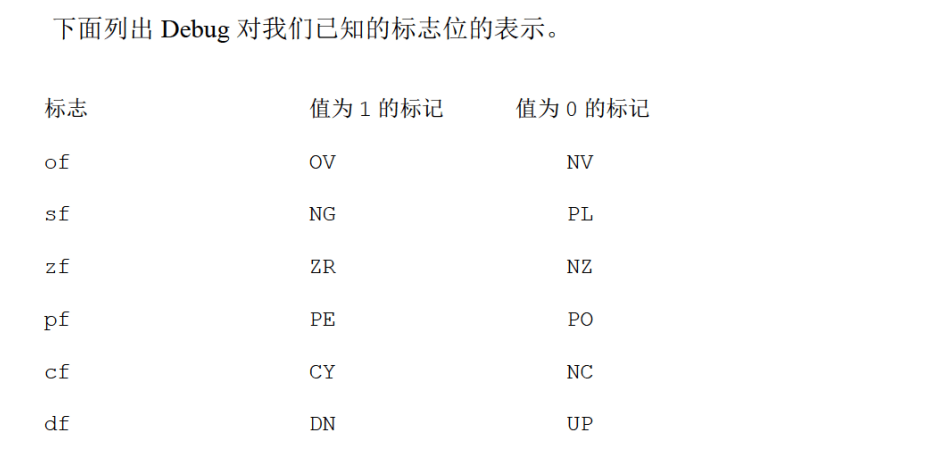
标志寄存器在Debug中的表示
实验 11 编写子程序
我们分析一下题目,以0结尾,我们可以通过cx实现自动循环。
难点在于我们如何识别出是小写字符az,应该是通过ASCII(97122)判断,如果ascii在这个区间,那么我们就通过and 1101 1111将第6位置零,如果不在此区间,那么直接下一个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 assume cs:codesg datasg segment db "Beginner's All-purpose Symbolic Instruction Code.",0 data ends codesg segment begin:mov ax,datasg mov ds,ax mov si,0 call letterc mov ax,4cooh int 21h letterc: s0 :mov cl,[si] mov ch,0 jcxz then cmp cl,97 jb over;如果小于97,进行下一个字符 cmp cl,122;如果大于122,进行下一个 ja over and cl,11011111b;如果在区间内则 mov [si],cl over :inc si jmp s0 then :ret codesg ends end begin
运行完我们使用d命令进行检测,全部都是大写,成功。
第十二章 内中断
内中断的产生
有四种中断源,前三个看不懂,但是最后这个int很熟悉,我们可以推测一下,int 21,21这个中断类型码代表的就是结束程序。CPU通过中断类型码来识别中断信息的来源。
中断过程
1.取得中断类型码
2.标志寄存器入栈
3.设置标志寄存器
4.CS的内容入栈
5.IP的内容入栈
6.读取入口地址
中断处理程序和iret指令 中断处理程序是存储在内存某段空间之中的,因为CPU随时都可能执行中断处理程序。中断处理程序的入口地址,即中断向量,必须存储在对应的中断向量表中。
iret指令相较于ret指令多了一步,让标志寄存器出栈
pop IP
pop CS
popf
向量表
实验 12 编写0号中断的处理程序
要点:1.中断处理程序一般存储在0000:0200~0000:02ff这256个字节中。
2.显示缓冲区 以B8000开始 25x80,25行80列,一列160个字节,两个字节显示一个字
3.我们想要现实的字符串,不能刚开始就存放在data段中,因为这个程序执行完之后,它所占用的内存空间被系统释放,在其中存放的字符串很可能会被别的信息覆盖,所以我们将字符串放置在do0程序中
1 2 3 do0 安装程序 将do0 的内容放在以0000 :0200 开头的那段空间中 设置中断向量表 将中断类型码0 对应的中断向量表改为do0 程序的起始地址 注意第一个字节是偏移地址,第二个字节是段地址 do0 程序 实现功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 assume cs:code code segment start:;do0安装程序 mov ax,cs mov ds,ax ;设置ds:si指向源地址(do0) mov si,offset do0;刚开始忘了设置si了,导致源地址指向了向量表 mov ax,0 mov es,ax mov di,200h ;设置es:di指向目的地址 mov cx,offset do0end-do0 cld ;设置传输方向为正 rep movsb ;逐字节传输 ;设置中断向量表 mov ax,0 mov es,ax mov word ptr es:[0],200h;通用的格式是[n*4] mov word ptr es:[2],0 ;检测程序 mov ax,1000h mov bh,1 div bh mov ax,4c00h int 21h do0:jmp short do0start db "divide erro!" do0start: mov ax,cx mov ds,ax mov si,202h ;设置es:di指向字符串,刚开始的jmp指令长度为两个字节 mov ax,0b800h mov es,ax mov di,12*160+36*2 ;第十三行,第36列 mov cx,12 ;cx为字符串长度 s: mov al,[si] mov es:[di],al mov es:[di+1],7ch inc si add di,2 loop s mov ax,4c00h int 21h do0end:nop code ends end start
第十三章 int 指令
BIOS和DOS所提供的中断例程
实验 13 编写、应用中断例程
这一题应该可以调用int 10的9号子程序吧,搭配2号子程序设置光标,但是9号子程序的结束标志是‘$’,看来是想让我们自己实现。
在网上看到了一种方法,先把安装程序执行,在运行测试程序,只要不重启DOSBox,就会保存我们设置的中断例程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ;编写安装程序 assume cs:code code segment start:mov ax,cs mov ds,ax mov si,offset ins ;设置ds:si指向源程序 mov ax,0 mov es,ax mov di,200h ;设置es:di指向目的地址 mov cx,offset insends-0ffset ins ;传输长度 cld ;正向传输 rep mobsb ;设置中断向量表 mov ax,0 mov es,ax mov word ptr es:[7ch*4],200h ;两个字节存一个地址 高地址存段 低地址存偏移 mov word ptr es:[ych*4+2],0 mov ax,4c00h int 21h ins:sub dh,1;这里注意000是第一行开始,160是第2行开始 mov al,160 mul dh;存入的数据是7*160,即第八行开始 mov bx,ax mov dh,0 add bx,dx add bx,dx;这里实现列数,注意两个字节表一个字符,所以我们加两次即加6 mov ax,0b800h mov es,ax mov al,cl s:mov cl,[si] mov ch,0 jcxz ok;如果是结束字符0,则跳转回去 mov es:[bx],cl mov es:[bx+1],al inc si add bx,2 jmp short s ok: iret insends:nop code ends end start
这里的ins程序和我们之前做的show_str十分吻合,我们直接copy过来,不要忘记将子程序使用的寄存器入栈然后反序出栈。
啊这个不就是书中的例子吗,自己尝试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ;编写安装程序 照着抄即可 assume cs:code code segment start:mov ax,cs mov ds,ax mov si,offset ins ;设置ds:si指向源程序 mov ax,0 mov es,ax mov di,200h ;设置es:di指向目的地址 mov cx,offset insends-offset ins ;传输长度 cld ;正向传输 rep movsb ;设置中断向量表 mov ax,0 mov es,ax mov word ptr es:[7ch*4],200h ;两个字节存一个地址 高地址存段 低地址存偏移 mov word ptr es:[7ch*4+2],0 mov ax,4c00h int 21h ins:push bp mov bp,sp dec cx jcxz lpret add [bp+2],bx ;给原来的ip加上位移 lpret:pop bp iret insends:nop code ends end start
本来ins那里
1 2 3 4 ins: dec cx jcxz lpret add [sp],bx ;给原来的ip加上位移
然后就出现了一个报错:must be index or base register 必须是索引寄存器或者base寄存器
也就是sp不能放在[]里单独使用,只有bx、si、di、bp (第八章)
看到后面的’$‘,不难看出下面将使用int 21的子程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 assume cs:code code segment s1: db 'Good,better,best,','$' s2: db 'Never let it rest','$' s3: db 'Till good is better','$' s4: db 'And better,best.','$' s : dw offset s1,offset s2,offset s3,offset s4 row: db 2,4,6,8 strat: mov ax,cs mov ds,ax mov bx,offset s mov si,offset row mov cx,4 ok: mov bh,0 mov dh,ds:[si] mov dl,0 mov ah,2 int 10h mov dx,ds:[bx] mov ah,9 int 21h add bx,2 int si,2 loop ok mov ax,4c00h int 21h code ends end strat
第十四章 端口 端口的读写 端口的读写指令只有两条,in和out,分别用于从端口读取数据和往端口写入数据
举个例子 (这里的in和out是针对 out就是从寄存器中出去)
1 2 3 mov dx,3f8h ;将端口号送入dx in al,dx ;从3f8h端口读入一个字节,就是将dx中的数据送入al out dx,al ;向3f8h端口写入一个字节,将al中的数据写入dx
CMOS RAM 芯片
1 2 3 mov al,2 out 70h,al in al,71h
逻辑位移指令 shl和shr
左移相当于x*2,右移相当于x/2。
实验 14 访问 CMOS RAM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 assume cs:code code segment start: mov cx,3 mov si,30 s: push cx add cx,6 mov al,cl out 70h,al in al,71h mov ah,al mov cl,4 shr ah,cl and al,00001111b add ah,30h ;以ascii表示 add al,30h mov bx,0b800h mov es,bx mov bx,si mov byte ptr es:[160*12+si+bx],ah mov byte ptr es:[160*12+si+bx+2],al mov byte ptr es:[160*12+si+bx+4],2fh add si,3 pop cx loop s mov cx,3 s2: push cx add cx,cx sub cx,2 push cx mov al,cl out 70h,al in al,71h mov ah,al mov cl,4 shr ah,cl and al,00001111b add ah,30h ;以ascii表示 add al,30h mov bx,0b800h mov es,bx mov bx,si mov byte ptr es:[160*12+si+bx],ah mov byte ptr es:[160*12+si+bx+2],al pop cx jcxz ok ;如果没有这一步的化,最后秒后面会多出一个冒号 mov byte ptr es:[160*12+si+bx+4],3ah ;冒号的ascii add si,3 pop cx loop s2 ok:mov ax,4c00h int 21h code ends end start
第十五章 外中断 用两个16位寄存器来存放32位的循环次数,这里刚开始没看懂,在网上找到了一个恍然大悟
1 2 3 4 5 6 7 8 mov ds,10h mov ax,0 s: sub ax,1 ;第一次ax=fffffh,cf=1 sbb dx,0 ;第一次dx=fh cmp ax,0 jne s cmp dx,0 jne s
上述程序实现了循环100000次。sbb dx,0 相当于dx=dx-0-CF,每循环(ffffh+1)即10000h次,dx减1.注意这里dx减1,发生在每10000次循环的最开始哦。
sti和cli指令
下面的程序用于改变全屏的显示信息非常的炫酷
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 assume cs:code stack segment db 128 dup (0) stack ends code segment start:mov ax,stack mov ss,ax mov sp,128 push cs pop ds mov ax,0 mov es,ax mov si,offset int9 mov di,204h mov cx,offset int9end-offset int9 cld rep movsb push es:[9*4] pop es:[200h] push es:[9*4+2] pop es:[202h] cli mov word ptr es:[9*4],204h mov word ptr es:[9*4+2],0 sti mov ax,4c00h int 21h int9: push ax push bx push cx push es in al,60h ;接收键入的字符 pushf call dword ptr cs:[200h] cmp al,3bh jne int9ret mov ax,0b800h mov es,ax mov bx,1 mov cx,2000 s: inc byte ptr es:[bx] add bx,2 loop s int9ret:pop es pop cx pop bx pop ax iret int9end:nop code ends end start
实验 15 安装新的int9中断例程
这次实验我们只需要更改上面程序int9的部分即可,A的通码1E,断码9E
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 assume cs:code stack segment db 128 dup (0) stack ends code segment start:mov ax,stack mov ss,ax mov sp,128 push cs pop ds mov ax,0 mov es,ax mov si,offset int9 mov di,204h mov cx,offset int9end-offset int9 cld rep movsb push es:[9*4] pop es:[200h] push es:[9*4+2] pop es:[202h] cli mov word ptr es:[9*4],204h mov word ptr es:[9*4+2],0 sti mov ax,4c00h int 21h int9: push ax push bx push cx push es in al,60h ;接收键入的字符 pushf call dword ptr cs:[200h] cmp al,1eh ;A的通码 je int9ret cmp al,9eh jne int9ret mov ax,0b800h mov es,ax mov bx,0 mov cx,2000 s: mov byte ptr es:[bx],65 add bx,2 loop s int9ret:pop es pop cx pop bx pop ax iret int9end:nop code ends end start
第十六章 直接定址表 描述了单元长度的标号
1 2 3 4 code segment a db 1,2,3,4,5,6,7,8 b dw 0 ;这里的a其实可以理解为数组的首地址a[0]是1
1 2 3 a:db 1,2,3,4 b:dw 0 ;这种用法是代码段中特有的 即使用 :
将标号当作数据来使用 1 2 3 4 5 data segment a db 1,2,3,4,5 b dw 0 c dw a,b ;c dd a,b data ends
相当于
1 2 3 4 5 data segment a db 1,2,3,4,5 b dw 0 c dw offset a,offset b ;c dw offset a,seg a,offset b,seg b data ends
seg 取段地址
实验 16
具体的功能怎么实现,书中写的很清楚,我们的任务是确定整个程序的框架。
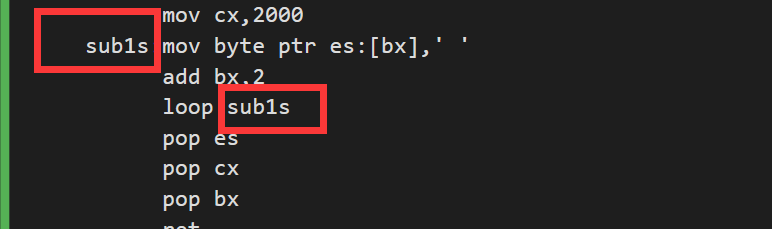
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 assume cs:code stack segment db 64 dup(0) stack ends code segment start:;安装新的int7ch mov ax,stack mov ss,ax mov sp,64 mov ax,cs mov ds,ax mov ax,offset int7ch mov si,ax mov ax,0 mov es,ax mov di,200h mov cx,offset int7chend-offset int7ch cld rep movsb cli mov word ptr es:[7ch*4],200h mov word ptr es:[7ch*4+2],0 sti mov ax,4c00h int 21h int7ch: jmp short set table dw offset sub1-offset int7ch+200h dw offset sub2-offset int7ch+200h dw offset sub3-offset int7ch+200h dw offset sub4-offset int7ch+200h set:push bx cmp ah,3 ja sret mov bl,ah mov bh,0 add bx,bx call word ptr cs:[bx+202h] ;这里的cs是跳转到int7ch之后的cs,加202是因为前面的jmp short set占了两个字节 sret:pop bx iret sub1:push bx ;清屏 push cx push es mov bx,0b800h mov es,bx mov bx,0 mov cx,2000 sub1s:mov byte ptr es:[bx],' ' add bx,2 loop sub1s pop es pop cx pop bx ret sub2:push bx ;前景 push cx push es mov bx,0b800h mov es,bx mov bx,1 mov cx,2000 sub2s:and byte ptr es:[bx],11110000b or es:[bx],al add bx,2 loop sub2s pop es pop cx pop bx ret sub3:push bx ;背景 push cx push es mov cl,4 shl al,cl mov bx,0b800h mov es,bx mov bx,1 mov cx,2000 sub3s:and byte ptr es:[bx],10001111b or es:[bx],al add bx,2 loop sub3s pop es pop cx pop bx ret sub4:push cx ;滚动 push si push di push es push ds mov si,0b800h mov es,si mov ds,si mov si,160 mov di,0 cld mov cx,24 sub4s:push cx mov cx,160 rep movsb ;si和di的增加在此处进行 pop cx loop sub4s mov cx,80 mov si,0 sub4s1:mov byte ptr [160*24+si],' ' add si,2 loop sub4s1 pop ds pop es pop di pop si pop cx ret int7chend:nop code ends end start
其实我们这里使用table的方式有点麻烦
1 2 3 4 5 6 7 8 9 ; table dw offset sub1-offset int7ch+200h dw offset sub2-offset int7ch+200h dw offset sub3-offset int7ch+200h dw offset sub4-offset int7ch+200h ;call word ptr cs:[bx+202h] ;我们把上面这些替换成下面的 ;在int7ch前面加上 org 200h 表示偏移地址从200h处开始 table dw sub1,sub2,sub3,sub4 call word ptr table[bx]
没加那个org 200h是不行的
org 200H ;表示下一条地址从偏移地址200H开始,和安装后的偏移地址相同,若没有org 200H,中断例程安装后,标号代表的地址改变了,和之前编译器编译的有所区别
如果我们不加上org,那么这个table的偏移地址就是本程序中的偏移地址.可是为什么sub1,这种标号还是以200h为准的偏移?应该是因为,sub1作为一个标号能正确的复制过去,table作为一个标号复制不过去,是因为table是比较抽象的?隐式的?
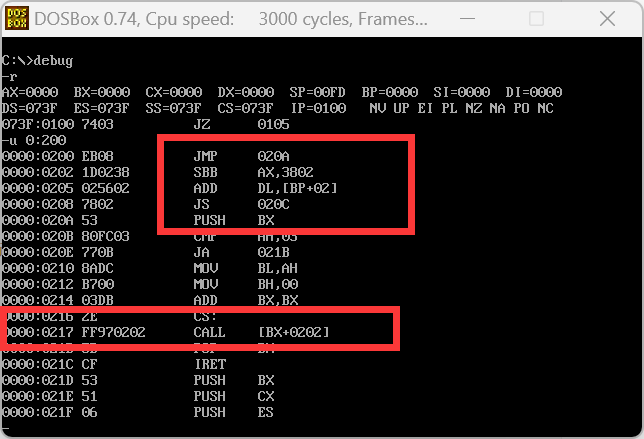
下面这张图是org 200h的,【bx+202h】
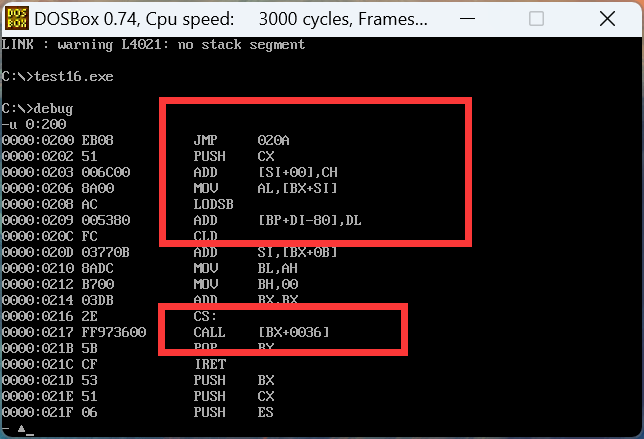
这张图是没有org的,我们可以看到下面的【bx+36h】,加的table的偏移地址
疑惑 为什么同样是标号,table复制过去是安装程序中的地址,sub传过去的就是200h的偏移地址???我觉得合理的解释是这个sub1s跟着一起复制了过去,就是第二个sub1s其实是随着第一个sub1s的变化而变化的。在程序执行完之后,主程序所占的内存被其他数据覆盖,之前的sub1消失,这么理解的话,标号代表的不一定是个固定不变的地址。
第十七章 使用BIOS进行键盘输入和磁盘读写